بازی اسنیک؛ آیا هوش مصنوعیها میتوانند بازی کردن را بیاموزند؟

اخیرا فکر و ذکرم درگیر هوش مصنوعی شده است. خصوصا سناریوهایی که بتوان در آن به هوش مصنوعی آموخت تا هدفی انتزاعی را برآورده کند بدون اینکه با مجموعهی دادهها تمرین ببیند یا دستورالعملهای واضحی از سیستم دریافت کند.
هوش مصنوعی ممکن است بیش از حد باد شده باشد، یا در جاهای اشتباه استفاده شده باشد، و معمولا برای خیلیها کلمهی گیجکنندهای است. بهجای لفاظی دربارهی اینکه هوش مصنوعی چگونه زندگیتان را عوض خواهد کرد (که خواهد کرد) یا چگونه شغلتان را میدزدد (که نمیدزدد)، این مقاله، در عوض، به مسئلهای ملموس و آشنا میپردازد:

بازی اسنیک
اسنیک قوانین سادهای دارد:
- شکل جهانْ شطرنجی و مربعی است.
- اسنیک تنها در زوایای قائم میتواند حرکت کند.
- این جهانْ مرزی دارد که اسنیک به محض برخورد با آن میمیرد.
- اسنیک هرگز نمیتواند بایستد یا متوقف شود.
- اگر اسنیک به بخشی از بدن خودش برخورد کند، میمیرد.
- هر وقت که اسنیک چیزی بخورد، بلندتر میشود.
- هدف این است که تا جای ممکن بلند شد و رشد کرد.
زمان انجام بازی، هر وقت که اسنیک قدمی رو به جلو میگذارد باید بین چند گزینه دست به تصمیم بگیرد: مستقیم برود، سمت چپ بپیچد یا سمت راست.
هدف ما ساخت هوش مصنوعیای است که بتواند این تصمیمات را خودش یاد بگیرد. ابتدا جهانی که اسنیک در آن هست ارزیابی میشود، سپس حرکتی را انتخاب میکند که او را زنده نگه داشته و به رشد او ادامه دهد.
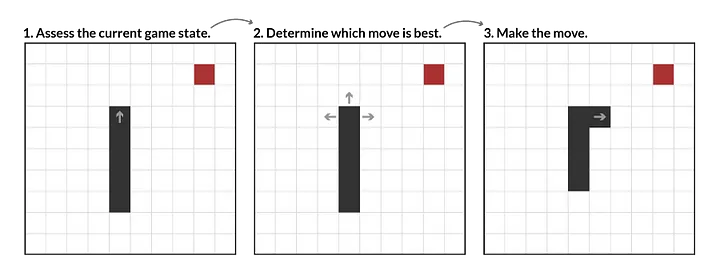
هوش مصنوعی ابتدا تعیین میکند در چه وضعیتی است، سپس تصمیم میگیرد دامنهی آزادیاش برای حرکت بعدی چقدر است، سپس دست به بهترین حرکت میزند (حرکت به سوی غذا).
انتخاب یک روش
روشها، الگوریتمها و فنون زیادی وجود دارند تا اسنیک را حل کرد. برخی از آنها زیر چتر هوش مصنوعی هستند. من فقط روی یک روش تمرکز خواهم کرد: جهش تصادفی ژنتیکی یک شبکهی نورونی/genetic random mutation of a neural network
به این دلایل که:
۱. دیگرانی که اسنیک را بازی کرده و رکوردهای بالا ثبت کردهاند، من به مجموع دادههای آنها دسترسی ندارم، پس نمیتوانم به شبکهی نورونیْ دادهای بدهم تا از روی آنها الگوبرداری کند.
۲. شخصا علاقه دارم ببینم آیا ممکن است منطق انجام بازی اسنیک را صرفا با جهشهای تصادفی به سیستم آموخت یا نه.
«جهش تصادفی ژنتیکی یک شبکهی نورونی» احتمالا ناآشناترین عبارتی است که در این مقاله خیلی از خوانندگان با آن برخورد میکنند — پس بیاییم آن را شکافته و قبل از آنکه ادامه دهیم به زیربنای آن بپردازیم.

شبکههای نورونی مثل یک سنتیسایزر ماژولار هستند. یک کلید را فشار میدهید، سیگنالی الکتریکی به پیکرهی مدارها ارسال میشود، مدارهایی که موزیسین قبلا آن را طراحی کرده تا آن صوت مطلوبش را دریافت کند — مثل یک صوت بم و تند، یا صوتی که به آرامی به پژواک درمیآید.
شبکهی نورونی چیست؟
شبکهی نورونی نوعی الگوریتم است که میتواند برای تعیین روابط انتزاعی بین دادههای ورودی و خروجی مطلوب استفاده شود. معمولا، شبکهی نورونی با تمرین دیدن بر اساس هزاران مثال [یا همان دادههای جمعآوریشده] به آن خروجی مطلوب ما میرسد. به مرور زمان، شبکه یاد میگیرد جنبههای مختلف دادههای ورودی چیست و مفیدترین آنها برای رسیدن به نتیجهی مطلوب کدام است. بنابراین، شبکهی نورونی به آرامی با ضرایب و دیگر فرمولهای پیچیده، دادههای ورودی را در هر مثالی که به او نشان داده میشود پردازش میکند.
شبکههای نورونی در اشکال، ابعاد و انواع مختلفی وجود دارند: پیچشی/convolutional، بازگشتی/recurrent، حافظهی کوتاه-مدت-بلند-مدت/long-short-term-memory و غیره. طراحی شبکهی نورونی مناسب برای مسئله میتواند سخت باشد، گیجکننده، و یکجور فوت کوزهگری بطلبد. اینجاست که «ژنتیک» وارد قضیه میشود.
الگوریتم ژنتیکی چیست؟
عوض اینکه یک نوع شبکهی نورونی انتخاب کرد و سپس به آرامی آن را بر اساس دیگر دادههای جمعآوریشده از بازی آموزش داد تا از آنها تقلید کند، ما میخواهیم سناریویی بسازیم که در آن هوش مصنوعی بدون داده و با اتکا به خودش بازی را بیاموزد.
تمام تغییراتی که بر شبکههای نورونی اعمال میشود تصادفی خواهند بود — و نه از طریق فیدبک مستقیم و راهنمایی قدم به قدم هوش مصنوعی. به مرور، تغییرات تصادفی کوچک در این شبکهی نورونی باعث ایجاد یک هوش مصنوعی کاملا کاربردی میشود چون تنها بازیکنان برتر در هر نسل زنده میمانند و تواناییشان را به نسل بعدی منتقل میکنند.
فرآیند تکاملی ما چنین عمل خواهد کرد:
۱. بهطور تصادفی با دکمه و سیمهای شبکهی نورونی ور میرویم [یعنی پارامترهایی که وارد سیستم میکنیم اعداد تصادفی هستند] تا هر بازی اسنیک خاص خودش باشد.
۲. هر یک از این شبکههای نورونی را برای انجام بازی اسنیک آزاد میگذاریم.
۳. بعد از اینکه هر شبکهی نورونی بازی را تمام کرد، تعیین میکنیم کدامیک از آنها عملکرد بهتری داشتند.
۴. با اعمال تغییرات تصادفی بر شبکههای نورونی که عملکرد بهتری از خود نشان دادند، دوباره نسل جدیدی از شبکههای نورونی با قابلیتهای خاص خودشان میسازیم.
۵. بازگشت به مرحلهی دوم و تکرار مراحل بعدی.
پس حالا میتوانیم آرام لم بدهیم و بگذاریم تا هوش مصنوعی بهطور طبیعی تکامل پیدا کند، نه؟ اشتباه است.
هوش مصنوعی هنوز هم به یک طراح نیازمند است
الگوریتم ژنتیکی باعث میشود از اینکه به مجموع دادههای مختلف دسترسی داشته و آن را برای آموزش به سیستم بدهیم معاف شویم، اما هنوز هم به عهدهی ماست (طراح) تا کلیات سیستم را طراحی کرده و این قابلیت را فعال کنیم. مخصوصا، باید دادهی ورودی و خروجی را انتخاب کنیم و تصمیم بگیریم «عملکرد خوب» در اسنیک دقیقا به چه معناست [یعنی خود سیستم نمیتواند بفهمد کدام نسل توانسته اسنیک را بهتر بازی کند و باید خود اپراتور انسانی آن را مشخص کند]. برای اینکه به استعارهای که قبلا دربارهی سنیتایزر زدیم هم ربط داشته باشد: ما هنوز هم باید خودمان کیبورد و بلندگو بسازیم و تعیین کنیم چه صدایی را میخواهیم بشنویم.
اولین قدم برای تعیین دادهی ورودی این است که شبکهی نورونی همان اطلاعاتی را داشته باشد که ما داریم. ما بازی را با نگاه به تصویر انجام میدهیم و رنگ پیکسلهایی که محیط بازی را تشکیل داده میبینیم. با این حال، این محتاج شبکهی نورونیای است که بتواند بین همهی قوانین اسنیک، که اول مقاله برشمردیم، ارتباط برقرار کند. یعنی بداند مرز محیط کجاست، اسنیک کجاست، مسیرش کجاست، غذا چیست و چگونه باید به آن برسد. و چون هر یک از اینها پیکسلی است با رنگ متفاوت، دادهی ورودی هم باید رنگ همهی این پیکسلها را داشته باشد، که میشود صدها یا شاید هزارها ورودی. این بههیچوجه غیرممکن نیست — اما مثل پیچاندن لقمه دور است.
طراحی از دیدگاه هوش مصنوعی
تصور کنید اسنیک را با زاویه دید اول شخص انجام میدهیم. خودتان را جای اسنیک بگذارید. به جهانی که تصور میکنید عمق بدهید و تجسم کنید چگونه برای عدم برخورد با دیوارها به سمت چپ و راست میپیچید، و همینطور «دیوارهای» جسم و دمتان.

اسنیک اگر زاویه دید اول شخص داشت احتمالا همهچیز را شبیه این اسکرینسیور ویندوز ۹۵ میدید.
برای انجام چنین نسخهای از اسنیک، تنها لازم است دو چیز را بدانید:
۱. مسیر رسیدن به غذا کجاست؟
۲. برای اینکه نمیرم باید در چه جهتهایی حرکت کنم؟
همینطور که اشکال شبکهی نورونی بین حرکت و مردن رابطه پیدا میکنند [یعنی با آزمون و خطا یاد میگیرد در برخورد با چه چیزهایی میمیرد و بهتر است دفعهی بعدی با آنها برخورد نکند]، قابلیت اجتناب از دیوارهای محیط و برخورد با جسم خود مار در یک قدم حل میشود. علاوه بر این، عوض اینکه به شبکهی نورونی بگوییم کجاست و برای رسیدن به غذا باید کجا برود، برای تعریف غذا برای هوش مصنوعی صرفا میگوییم «مستقیم برو»، «بپیچ سمت چپ»، «بپیچ سمت راست»، یا «پشت سرت». بنابراین دیگر این شبکهی نورونی نیاز ندارد بفهمد سایز محیطی که در آن است چقدر است، اشیای مختلف در آن محیط چه هستند، و اصلا در چه جهتی دارد میرود. وقتی خودتان را جای هوش مصنوعی بگذارید و بر اساس دیدگاه او دست به طراحی بزنید، میبینیم مشکل بهمراتب سادهتر شده و هوش مصنوعی هم راحتتر آن را حل میکند.
دنبال هیاهو نروید، مشکل را حل کنید
متعصبین ممکن است بگویند با صرف نظر از طراحی بخشهای سختتر یکجورهایی تقلب کردیم — بهشدت مخالفم. وقتی هدفتان کار روی یک نوع هوش مصنوعی با کارکردهای کلی است (یعنی هوش مصنوعیای که بتواند کارهای دیگری غیر از اسنیکبازیکردن انجام دهد) حرف آنها درست است اما ما روی یک فناوری خیلی جزئی کار میکنیم و بهتر است همینگونه با آن رفتار شود. تعیین اینکه از هر جز کجا و چگونه استفاده کرد به راهحل قابلفهمتر و سریعتری ما را میرساند.
آیا میشد اسنیک را با روشهای قانونمحور حل کرد؟ البته. ما صرفا میخواهیم ببینیم آیا تحت شرایط لازم، آن قوانین میتوانند بهطور تصادفی شکل بگیرند یا نه.
این چه سر و شکلی به طراحی ما میدهد؟ به چیزی شبیه تصویر زیر تبدیل میشود:

هر اطلاعاتی که به شبکهی نورونی ارسال و سپس نتیجهاش دریافت میشود باید بین صفر و یک باشد. برای این هدف، ما تمام دادههای ورودی را به سوالاتی که جوابشان یا «آری» است یا «نه» (دربارهی جهتهای مسیریابی) خلاصه کردیم. مهم است به یاد داشته باشیم شبکهی نورونی هیچ نمیداند این اعداد چه معنایی دارند یا حتی دو مجموعه سهتایی هستند. هوش مصنوعی تنها برآیند آنها که عدد ۶ است را میبیند.
داده های خروجی هم بهطور مشابهی خلاصه شدهاند. ما از شبکهی نورونیمان میپرسیم که سه عدد به ما برگرداند. سپس بالاترین عدد را برداشته و از آن، همانطور که بالاتر نوشته شد، برای جهتدهی به اسنیک استفاده میکنیم. شبکهی نورونی البته هیچ نمیداند این اعداد برای چه هستند یا چگونه بعدا [توسط انسان] قرار است استفاده شوند.
قرار است ورژنهای متعددی از این شبکهی نورونی را تولید کنیم و بگذاریم هر یک از آنها در حرکت دادن اسنیک در محیط آزاد باشد. آنهایی که بهترین عملکرد را داشته باشند نوعی اتصال بین دادههای ورودی و خروجی یافتهاند که توانسته آنها را برای مدت طولانیتری زنده نگه دارد. به مرور زمان پارامتر آن اسنیکهایی که بالاترین امتیاز را گرفتهاند دستکاری میکنیم — و سرانجام هوش مصنوعیای داریم که میتواند بازی اسنیک را انجام دهد.
تعریف عملکرد خوب
این ما را به آخرین مسئله در طراحی میرساند: وقتی میگوییم «بهترین عملکرد» در اسنیک، یعنی چه؟ در حوزهی یادگیری تقویتی/reinforcement learning به آن کارکرد پاداش/reward function میگویند.
قدم اول درست این است که مکانیسم امتیازدهی بازی را بازتولید کرد. بنابراین هرقدر اسنیک بلندتر شود، امتیاز هم بالاتر میرود. این بهخودیخود خوب کار میکند، اما خیلی وقتگیر است چون برای شبکهی نورونی واضح نیست که اگر به سمت غذا قدم بردارد برایش خوب است. حالا سعی میکنیم این مشکل را ساده کنیم — پس به ازای هر قدمی که اسنیک به سمت غذا برمیدارد ۱ امتیاز به دست میآورد و هر گاه به غذا رسید ۱۰ امتیاز دیگر میگیرد.

متاسفانه، این شبکهی نورونی در تعریف ما از «عملکرد خوب» یک راه گزیر پیدا کرده و متوجه شده اگر دایرهوار دور خود بچرخد به امنترین و بهترین شکل میتواند امتیاز بگیرد. عدد بالای سمت چپْ امتیاز این شبکهی نورونی است. و غذاْ دایرهی سبز است.
به همین سادگی حل شد؟ اشتباه.
همانطور که در چپ تصویر دیده میشود، تعریف ما از «عملکرد خوب» به یک راه گریز/loophole برای سیستم تبدیل شد. با دور خود چرخیدن، هوش مصنوعی میتواند امتیاز بیشتری بگیرد بدون اینکه با خطر برخورد با دیوار یا دم رو-به-رشدش روبهرو شود. کارکردهای پاداشْ درست پیادهسازیشان سخت ولی خرابکردنشان شدیدا راحت است. برای همین است که در بعضی از سناریوها به اپراتور انسانی است تا ماشین را راهنمایی و تعیین کند نتیجهی درست چیست، عوض اینکه برای مشکلی ذهنی بخواهد کارکرد پاداش عینیای تحمیل کند.
خوشبختانه این راه گزیر به سادگی حل میشود. میتوانیم کارکرد پاداش را اینطوری پیاده کنیم که اگر اسنیک قدمی برخلاف مسیر غذا بردارد از امتیازش کسر میشود. پس هر قدم به سوی غذا ۱ امتیاز دارد و هر قدم برای دوری از آن ۱.۵ امتیاز منفی. بنابراین اگر اسنیک بخواهد دایرهوار دور خود بچرخد امتیاز منفی بیشتری میگیرد و مجبور است از حاشیهی امن خارج شود.
تکاملی که میشود شاهدش بود
سرانجام، باید تصمیم بگیریم سایز هر نسل چقدر است و چگونه هر شبکهی نورونی برای تولید نسل بعدی باید دست به انتخاب بزند. از آنجایی که میخواهم هوش مصنوعی برای همه دسترسپذیر باشد و مشاهدهکردنش هم آسان، میخواهم برنامهام را طوری بسازم که خیلی راحت روی مرورگرها هم اجرا شود. بنابراین سایز جمعیت اسنیکها را نسبتا کوچک انتخاب میکنیم. از آنجا که یک صفحهی شطرنجی ۵ در ۱۱ خیلی خوب روی صفحهی مرورگر من جا میگیرد، من ۵۵ اسنیک را انتخاب میکنم — و ۶ اسنیک برتر (تقریبا ۱۰ درصد اسنیکها) برای تولید نسل بعدی اسنیکها انتخاب میشوند.
هر نسل تا زمانی باقی است که هر ۵۵ اسنیک نمرده باشند یا آنها که باقی ماندهاند امتیاز منفی نداشته باشند. این باعث میشود نسلهای اولیه عمر کوتاهی داشته باشند، تا بالاخره آنقدر جهش بیایبند که متوجه شوند «اگر چیزی جلویم قرار داد [دم یا دیوار] مرا به سمت دیگری حرکت ده» و آن را به نسلهای بعدی منتقل کنند.
از آنجایی که این مشکل را سادهسازی کردیم و با دقت همهچیز را از دیدگاه هوش مصنوعی گذرانیم، خیلی طول نمیکشد تا شبکههای نورونی آنقدر تکامل بیابند تا به آن «عملکرد خوب»ای که میخواهیم برسند. بعد از گذشت دوجین نسل، پیشرفت و عملکرد اسنیکها چشمگیر میشود. هر نسل البته جهشهایی پیدا میکند که مفید نیستند، و مثلا اسنیکهایی که دور خود تاب میخورند امتیاز کم و کمتری میگیرند و عملکرد خود را به نسل بعدی منتقل نمیکنند اما آنهایی که عملکرد خوبی دارند این دانش را به نسل آینده منتقل کرده و مدام باعث پیشرفتش میشوند.
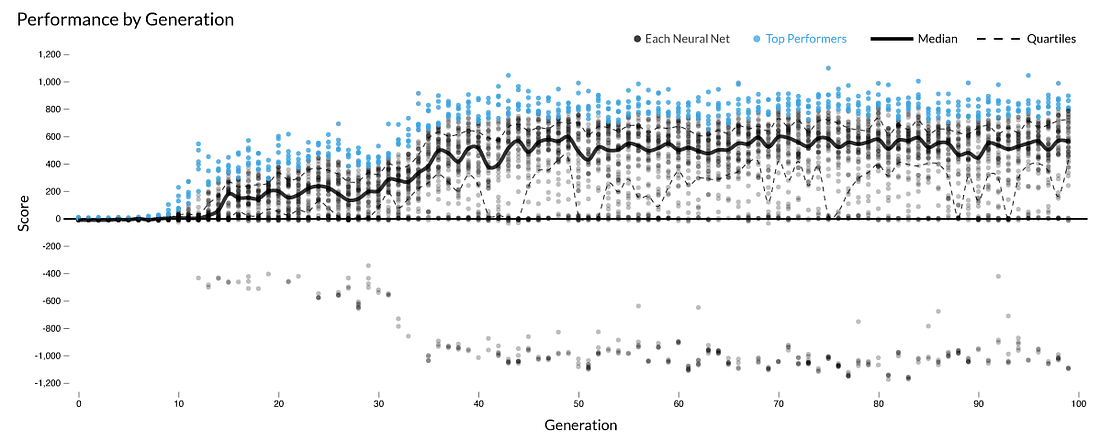
هر نسل، ۵۵ شبکهی نورونی متفاوت دارد. امتیاز هر یک از آنها وابسته به کارکرد پاداشی است که بالاتر شرحش رفت.
بعد از گذشت ۱۰۰ نسل، میبینیم استراتژی تکاملیافته در واقع محتاج این است که شبکههای نورونی هر از گاهی امتیاز از دست بدهند. بهجای اینکه اسنیکها حالا دنبال سریعترین راه باشند، مسیری خلاف غذا میروند تا موقعیت خود را بازتنظیم کرده و مواظب باشند با دم خود برخورد نکنند. اینکه هوش مصنوعی به این نکته پی میبرد غافلگیرکننده است چون شبکههای نورونیای که ساختیم هیچ از سایز محیطی که در آن هستند خبر ندارند و تنها فضای جلوی رویشان را میبینند. اینکه چگونه این ویژگی تکامل پیدا کرد جای سوال است و گرچه هر تلاشی برای تکامل مجددْ به نتیجهی متفاوتی میرسد، اما سرانجام، در پایان همهی این نسلها، اسنیکها کم و بیش همین رفتار را خودبهخود یاد میگیرند.
هیاهوی هوش مصنوعیها، تغییرات صنعتی، یا کمپینهای تبلیغاتی بد از سوی کمپانیهای بزرگ تکنولوژیک نباید حواستان را پرت کند. روی کار پیشرو تمرکز کرده و با جدیت و دقت توضیح دهید میخواهید هوش مصنوعی چه کاری برایتان انجام دهد.
هوش مصنوعی برای خیلی از مشکلات ابزار قدرتمندی میتواند باشد — اما هنوز هم نیازمند یک طراح انسانی است. طراحان خوب نیز با جدیت به مشکلات پیچیده فکر کرده و خودشان را طولانیمدت جای کاربری که قرار است از آن استفاده کند میگذارند. طراحی هوش مصنوعیها هم ازایننظر فرقی ندارد.
نویسنده: Peter Binggeser